Refer to Exhibit.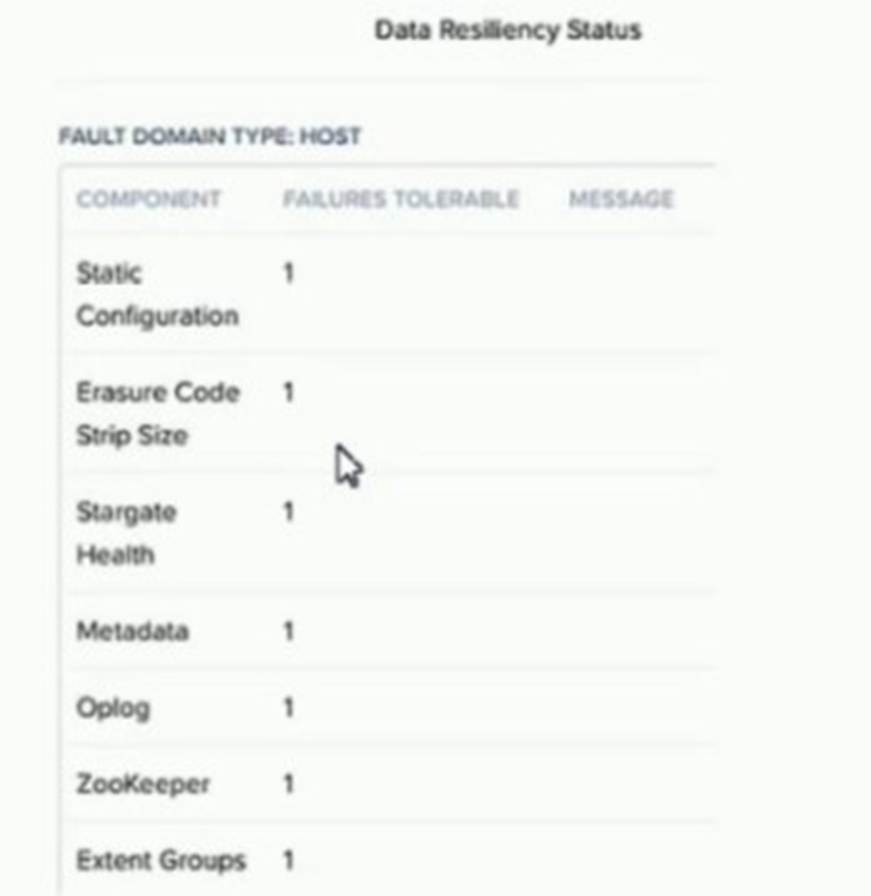
An administrator increases the cluster RF to 3. The containers are not modified.
What will the new values in the data resiliency dashboard be for FAILURES TOLERABLE for the Zookeeper and Extent Groups components?
Correct Answer:
C
According to the web search results, the cluster redundancy factor (RF) determines how many copies of the cluster metadata and configuration data are stored on different nodes. By default, the cluster RF is 2, which means that there are three copies of the Zookeeper and Cassandra data on the cluster. If the cluster RF is increased to 3, then there will be five copies of the Zookeeper and Cassandra data on the cluster12. This means that the Zookeeper component can tolerate two failures, as it can still operate with a quorum of three nodes out of five3.
However, the container replication factor (RF) determines how many copies of the VM data and oplog are stored on different nodes. The container RF can be set independently for each container, and it can be different from the cluster RF. For example, a container can have RF 2 even if the cluster has RF 34. In this case, the container will only have two copies of the VM data and oplog on the cluster, regardless of the cluster RF. This means that the Extent Groups component can only tolerate one failure, as it needs at least one copy of the VM data and oplog to be available5.
Therefore, if the administrator increases the cluster RF to 3, but does not modify the containers, then the new values in the data resiliency dashboard will be Zookeeper = 2 and Extent Groups = 1.
Prism Central will be installed manually on an AHV cluster.
Which three disk images must be downloaded from the portal for the Prism Central VM? (Choose three.)
Correct Answer:
CDE
https://portal.nutanix.com/page/documents/details?targetId=Prism-Central- Guide-Prism-v5_10:mul-pc-install-scratch-c.html
According to the Nutanix Support & Insights web search result4, Prism Central can be installed manually on an AHV cluster by using three disk images: boot, home, and data. These disk images must be downloaded from the portal for the Prism Central VM and uploaded to an image service on the AHV cluster. The boot image contains the operating system and kernel for Prism Central. The home image contains the configuration files and logs for Prism Central. The data image contains the database and application files for Prism Central.
A recently configured cluster is leveraging NearSync with a recovery schedule of 15 minutes. It is noticed that the cluster is consistently transitioning in an Out of NearSyne.
What action should be taken to potentially address this issue?
Correct Answer:
A
One of the possible reasons for a cluster to transition out of NearSync is insufficient network bandwidth between the source and target clusters. NearSync requires a minimum network bandwidth of 10 Mbps per VM for replication3. If the network bandwidth is lower than the required amount, the replication of recovery points may take longer than the configured RPO, resulting in an Out of NearSync condition. To address this issue, you can increase the network bandwidth between the clusters or reduce the number of VMs protected by NearSync4.
References: 1: Stargate - Nutanix Bible 2: Nutanix Cluster Architecture Overview - Nutanix Bible 3: NearSync Disaster Recovery (RPO <= 15 minutes) - Nutanix Support &
Insights 4: Transitioning in and out of NearSync - Nutanix Support & Insights
Microsegmentation was recently enabled in a Nutanix environment. The administrator wants to leverage Prism Central to create a policy that will block all traffic regardless of direction, between two groups of VMs identified by their category.
Which policy should be used to meet this requirement?
Correct Answer:
D
According to the web search results, the policy that should be used to meet this requirement is an Isolation Environment Policy. An Isolation Environment Policy is a type of security policy that can be created in Prism Central using Flow Network Security, which is a feature that provides microsegmentation and network security for Nutanix environments1. An Isolation Environment Policy allows the administrator to isolate a group of VMs from another group of VMs based on their categories, and block all traffic between them regardless of direction2. This policy can be useful for creating isolated environments for testing, development, or compliance purposes2.
In the event of a disk failure, which process will immediately ad automatically scans Cassandra to find all data previously hosted on the failed disk, and all disks in that node?
Correct Answer:
A
Curator is the process that runs on every node in a Nutanix cluster and is responsible for data management tasks such as deduplication, compression, erasure coding, and replication factor compliance. Curator also handles disk failure recovery by scanning Cassandra to find all data previously hosted on the failed disk, and all disks in that node. Curator then rebuilds the data on other nodes in the cluster using the distributed storage fabric1.
