A data scientist has defined a Pandas UDF function predict to parallelize the inference process for a single-node model:
They have written the following incomplete code block to use predict to score each record of Spark DataFramespark_df:
Which of the following lines of code can be used to complete the code block to successfully complete the task?
Correct Answer:
B
To apply the Pandas UDFpredictto each record of a Spark DataFrame, you use themapInPandasmethod. This method allows the Pandas UDF to operate on partitions of the DataFrame as pandas DataFrames, applying the specified function (predictin this case) to each partition. The correct code completion to execute this is simply mapInPandas(predict), which specifies the UDF to use without additional arguments orincorrect function calls.References:
✑ PySpark DataFrame documentation (Using mapInPandas with UDFs).
Which of the following describes the relationship between native Spark DataFrames and pandas API on Spark DataFrames?
Correct Answer:
C
Pandas API on Spark (previously known as Koalas) provides a pandas-like API on top of Apache Spark. It allows users to perform pandas operations on large datasets using Spark's distributed compute capabilities. Internally, it uses Spark DataFrames and adds metadata that facilitates handling operations in a pandas-like manner, ensuring compatibility and leveraging Spark's performance and scalability. References
✑ pandas API on Spark
documentation:https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/index.html
A data scientist learned during their training to always use 5-fold cross-validation in their model development workflow. A colleague suggests that there are cases where a train- validation split could be preferred over k-fold cross-validation when k > 2.
Which of the following describes a potential benefit of using a train-validation split over k- fold cross-validation in this scenario?
Correct Answer:
E
A train-validation split is often preferred over k-fold cross-validation (with k > 2) when computational efficiency is a concern. With a train-validation split, only two models (one on the training set and one on the validation set) are trained, whereas k-fold cross- validation requires training k models (one for each fold).
This reduction in the number of models trained can save significant computational resources and time, especially when dealing with large datasets or complex models. References:
✑ Model Evaluation with Train-Test Split
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.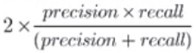
Which of the following suggestions should the team include in their guidelines?
Correct Answer:
C
The F1 score is the harmonic mean of precision and recall and is particularly useful in situations where there is a significant imbalance between positive and negative classes. When there is a class imbalance, accuracy can be misleading because a model can achieve high accuracy by simply predicting the majority class. The F1 score, however, provides a better measure of the test's accuracy in terms of both false positives and false negatives.
Specifically, the F1 score should be used over accuracy when:
✑ There is a significant imbalance between positive and negative classes.
✑ Avoiding false negatives is a priority, meaning recall (the ability to detect all positive instances) is crucial.
In this scenario, the F1 score balances both precision (the ability to avoid false positives) and recall, providing a more meaningful measure of a model??s performance under these conditions.
References:
✑ Databricks documentation on classification metrics: Classification Metrics
A machine learning engineer is trying to perform batch model inference. They want to get predictions using the linear regression model saved at the pathmodel_urifor the DataFramebatch_df.
batch_dfhas the following schema: customer_id STRING
The machine learning engineer runs the following code block to perform inference onbatch_dfusing the linear regression model atmodel_uri:
In which situation will the machine learning engineer??s code block perform the desired
inference?
Correct Answer:
A
The code block provided by the machine learning engineer will perform the desired inference when the Feature Store feature set was logged with the model at model_uri. This ensures that all necessary feature transformations and metadata are available for the model to make predictions. The Feature Store in Databricks allows for seamless integration of features and models, ensuring that the required features are correctly used during inference.
References:
✑ Databricks documentation on Feature Store: Feature Store in Databricks
